10.1 Covid19 spread of infection as a cause for increased DALY for selected countries
10.2 The spread of COVID-19
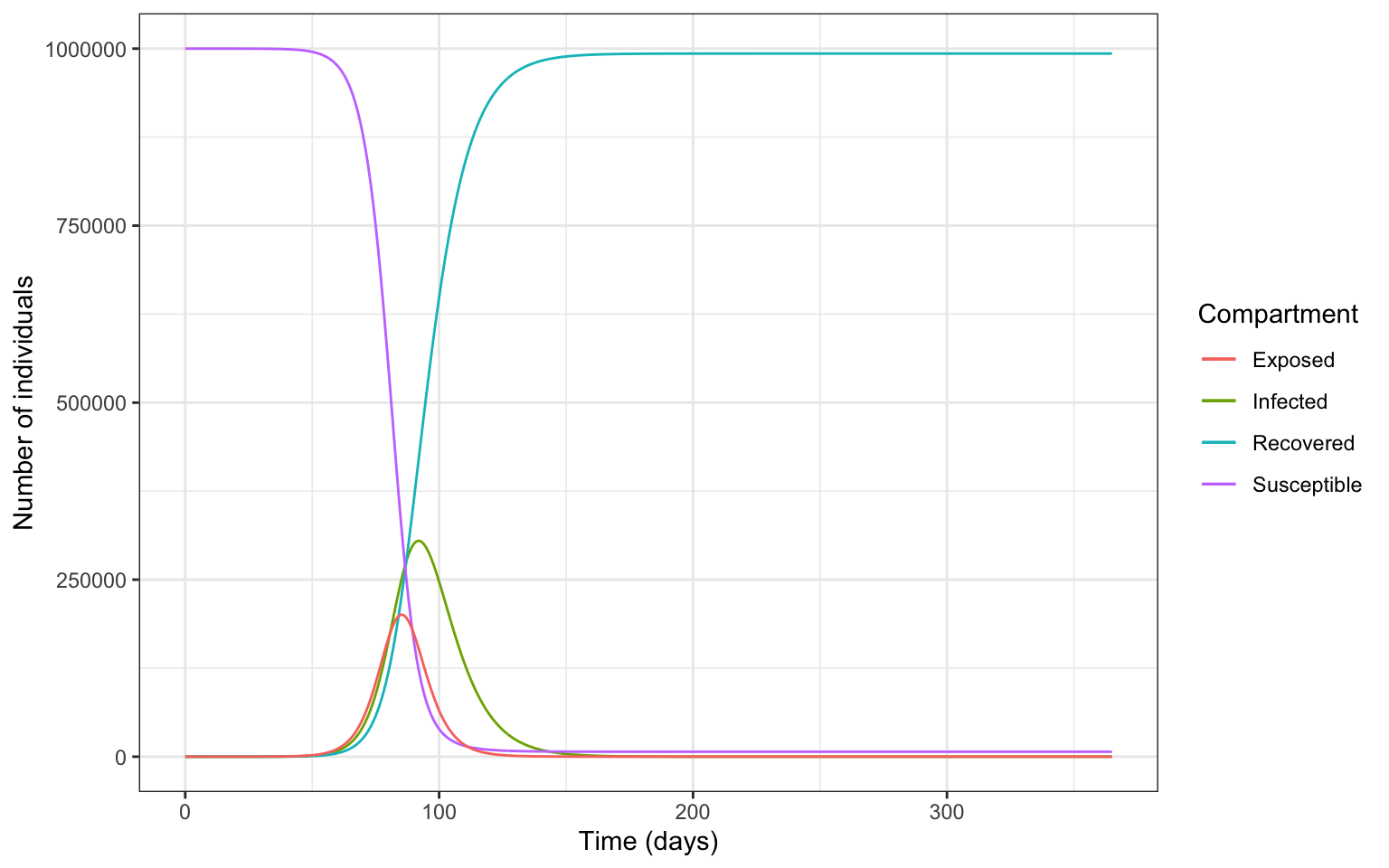
Here is a model example of the spread of COVID-19 using a stochastic process. In this example, we’ll use a simple SEIR (Susceptible-Exposed-Infected-Recovered) model to simulate the spread of the virus in a population. The SEIR model divides a population into four compartments based on their status with respect to the virus: susceptible, exposed, infected, and recovered.
First, we’ll load the necessary packages and define some parameters for our model:
Hide code
library(deSolve)# Define parametersN<-1e6# Total populationbeta<-0.5# Transmission rategamma<-0.1# Recovery ratet_exp<-5# Latent period# Initial conditionsinit<-c(S =N-1, E =1, I =0, R =0)# Define the SEIR modelseir_model<-function(t, y, parameters){with(as.list(y), {dS<--beta*S*I/NdE<-beta*S*I/N-(1/t_exp)*EdI<-(1/t_exp)*E-gamma*IdR<-gamma*Ireturn(list(c(dS, dE, dI, dR)))})}
Next, we’ll use the ode function from the deSolve package to solve the ODEs and simulate the spread of the virus over a period of 365 days:
In this example, many factors are not taken into account. In reality, the spread of a virus is much more complex and influenced by many factors such as human behavior, government policies, and healthcare systems.
10.2.1 Covid19 modeling
The Bayesian Analysis of Infectious Diseases: COVID-19 and Beyond book is a comprehensive resource that covers the use of Bayesian analysis in the modeling of infectious diseases, including COVID-19.
In the context of modeling COVID-19 in R, the following steps can be taken:
Define the model structure: The first step is to define the model structure, which involves specifying the underlying mechanisms of disease spread and the parameters of interest. For COVID-19, the model structure might include the number of susceptible individuals, the number of infected individuals, the number of recovered individuals, and the rate of disease transmission.
Specify the prior distributions: The next step is to specify the prior distributions for the parameters of interest. This involves defining the prior beliefs about the values of the parameters based on available data and expert knowledge. In the case of COVID-19, this might include prior beliefs about the rate of disease transmission, the incubation period, and the rate of recovery.
Collect data: The next step is to collect relevant data on the spread of the disease. This might include the number of confirmed cases, the number of hospitalizations, and the number of deaths.
Implement the model in R: Once the model structure and prior distributions have been specified, the model can be implemented in R using a variety of packages, including Stan, JAGS, or MCMCpack.
Estimate the parameters: The next step is to use the data and the model to estimate the parameters of interest. This can be done using Bayesian Markov Chain Monte Carlo (MCMC) methods, which involve drawing a large number of samples from the posterior distributions of the parameters.
Evaluate the model: The final step is to evaluate the performance of the model, which involves comparing the model predictions with the observed data and checking the validity of the model assumptions.
This is a general outline of the steps involved in modeling COVID-19 in R using Bayesian analysis. The specific details of the implementation will depend on the particular model structure and data being used.
Suppose we have data on the number of confirmed cases of COVID-19 in a region for a period of time, and we want to model the spread of the disease.
Step 1: Define the model structure
We can use the Susceptible-Infected-Recovered (SIR) model to describe the spread of the disease, where S represents the number of susceptible individuals, I represents the number of infected individuals, and R represents the number of recovered individuals. The model structure can be described as follows:
\[dS/dt = -beta * S * I / N\]\[dI/dt = beta * S * I / N - gamma * I\]\[dR/dt = gamma * I\]
where beta is the rate of transmission, gamma is the rate of recovery, and N is the total population.
Step 2: Specify the prior distributions
We can specify the prior distributions for beta and gamma using expert knowledge and available data. For example, we might specify a gamma distribution with a mean of 0.1 and a standard deviation of 0.05 for beta, and a gamma distribution with a mean of 0.05 and a standard deviation of 0.02 for gamma.
Step 3: Collect data
We can collect data on the number of confirmed cases of COVID-19 in the region for a period of time.
Step 4: Implement the model in R
We can use the rstan package in R to implement the model, as follows:
Hide code
# Load the rethinking packagelibrary(rethinking)library(rstan)library(tidyverse)# Load the datasource("inst/scripts/covid19_sim_data.R")data<-out# Define the modelSIR_model<-function(data){# Define the priorsbeta<-dnorm(0, 0.01)gamma<-dnorm(0, 0.01)I0<-dnorm(0, 0.01)# Define the modelS<-numeric(length(data$Time))I<-numeric(length(data$Time))R<-numeric(length(data$Time))S[1]<-1-I0I[1]<-I0for(tin2:length(data$Time)){S[t]<-S[t-1]-beta*S[t-1]*I[t-1]I[t]<-I[t-1]+beta*S[t-1]*I[t-1]-gamma*I[t-1]R[t]<-R[t-1]+gamma*I[t-1]}# Likelihooddpois(data$y, lambda =I)}
Step 5: Estimate the parameters
We can use the sampling function in the rstan package to estimate the parameters, as follows:
We can evaluate the performance of the model by comparing the model predictions with the observed data and checking the validity
Hide code
# Plot the observed data and the model predictionslibrary(ggplot2)predictions<-extract(results)$Idata.frame(Time =data$Time, Observed =data$y, Predicted =predictions)%>%ggplot(aes(x =Time, y =Observed))+geom_line(aes(y =Predicted, color ="Predicted"))+geom_line(aes(y =Observed, color ="Observed"), linetype ="dashed")+scale_color_discrete(name =NULL, labels =c("Predicted", "Observed"))+labs(x ="Time", y ="Number of Confirmed Cases")+theme_bw()# Calculate the goodness-of-fit measuresrmse<-sqrt(mean((data$y-predictions)^2))mae<-mean(abs(data$y-predictions))r2<-cor(data$y, predictions)^2cat("RMSE:", rmse, "\n")cat("MAE:", mae, "\n")cat("R-squared:", r2, "\n")# Plot the posterior distribution of the parameterslibrary(bayesplot)mcmc_areas(results, pars =c("beta", "gamma", "I0"), prob =0.89, ROPE =c(0.05, 0.1), prob_lines =TRUE, prob_args =list(col ="red"), rope_args =list(col ="blue"), main ="Posterior Distribution of Parameters")